This is the original WebCrawler paper, published and presented at the Second International WWW Conference in 1994. Other WebCrawler resources are available from Brian's home page.
Introduction
The Design of the WebCrawler
Observations and Lessons
Future Work
Conclusion
References
In large distributed hypertext system like the World-Wide Web, users find resources by following hypertext links. As the size of the system increases the users must traverse increasingly more links to find what they are looking for, until precise navigation becomes impractical. The WebCrawler is a tool that solves these problems by indexing and automatically navigating the Web. It creates an index by an incomplete breadth-first traversal, then relies on an automatic navigation mechanism to fill in the holes. The WebCrawler indexes both document titles and document content using a vector space model. Users can issue queries directly to the pre-computed index or to a search program that explores new documents in real time. The database the WebCrawler builds is available through a search page on the Web. Experience with this index suggests that the WebCrawler is collecting enough information from the Web, and that while the current query interface is adequate, more sophisticated retrieval tools are necessary. Real-time searches, although not available to the public, are fast and seem well targeted towards what what the user wants.
Imagine trying to find a book in a library without a card catalog. It is not an easy task! Finding specific documents in a distributed hypertext system like the World-Wide Web can be just as difficult. To get from one document to another users follow links that identify the documents. A user who wants to find a specific document in such a system must choose among the links, each time following links that may take her further from her desired goal. In a small, unchanging environment, it might be possible to design documents that did not have these problems. But the World-Wide Web is decentralized, dynamic, and diverse; navigation is difficult, and finding information can be a challenge. This problem is called the resource discovery problem.
The WebCrawler is a tool that solves the resource discovery problem in the specific context of the World-Wide Web. It provides a fast way of finding resources by maintaining an index of the Web that can be queried for documents about a specific topic. Because the Web is constantly changing and indexing is done periodically, the WebCrawler includes a second searching component that automatically navigates the Web on demand. The WebCrawler is best described as a "Web robot." It accesses the Web one document at a time, making local decisions about how best to proceed. In contrast to more centralized approaches to indexing and resource discovery, such as ALIWEB and Harvest [Koster, Bowman], the WebCrawler operates using only the infrastructure that makes the Web work in the first place: the ability of clients to retrieve documents from servers.
Although the WebCrawler is a single piece of software, it has two different functions: building indexes of the Web and automatically navigating on demand. For Internet users, these two solutions correspond to different ways of finding information. Users can access the centrally maintained WebCrawler Index using a Web browser like Mosaic, or they can run the WebCrawler client itself, automatically searching the Web on their own.
As an experiment in Internet resource discovery, the WebCrawler Index is available on the World-Wide Web. The index covers nearly 50,000 documents distributed on over 9000 different servers, answers over 6000 queries per day and is updated weekly. The success of this service shows that non-navigational resource discovery is important and validates some of the design choices made in the WebCrawler. Three of these choices stand out: content-based indexing to provide a high-quality index, breadth-first searching to create a broad index, and robot-like behavior to include as many servers as possible.
The first part of this paper describes the architecture of the WebCrawler itself, and some of the tradeoffs made in its design. The second part of the paper discusses some of the experience I have gained in operating the WebCrawler Index.
The most important feature of the World-Wide Web today is its decentralized nature. Anyone can add servers, documents, and hypertext links. For search tools like the WebCrawler, such a dynamic organization means that discovering new documents is an important piece of the design. For the WebCrawler itself, "discovering documents" means learning their identities; on the Web, those identities currently take the form of Uniform Resource Locators (URLs). The URLs can refer to nearly any kind of retrievable network resource; once the WebCrawler has a URL it can decide whether the document is worth searching and retrieve it if appropriate.
After retrieving a document, the WebCrawler performs three actions: it marks the document as having been retrieved, deciphers any outbound links (href's), and indexes the content of the document. All of these steps involve storing information in a database.
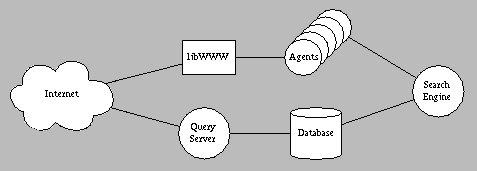
Figure 1: Software components of the WebCrawler
The WebCrawler has a software component for each of the activities described above; the components fit together as illustrated in Figure 1. In this architecture, the search engine directs the WebCrawler's activities. It is responsible for deciding which new documents to explore and for initiating their retrieval. The database handles the persistent storage of the document metadata, the links between documents, and the full-text index. The "agents" are responsible for retrieving the documents from the network at the direction of the search engine. Finally, the Query Server implements the query service provided to the Internet. Each of these components is described in detail below.
The WebCrawler discovers new documents by starting with a known set of documents, examining the outbound links from them, following one of the links that leads to a new document, and then repeating the whole process. Another way to think of it is that the Web is a large directed graph and that the WebCrawler is simply exploring the graph using a graph traversal algorithm.
Figure 2 shows an example of the Web as a graph. Imagine that the WebCrawler has already visited document A on Server 1 and document E on Server 3 and is now deciding which new documents to visit. Document A has links to document B, C and E, while document E has links to documents D and F. The WebCrawler will select one of documents B, C or D to visit next, based on the details of the search it is executing.
The search engine is responsible not only for determining which documents to visit, but which types of documents to visit. Files that the WebCrawler cannot index, such as pictures, sounds, PostScript or binary data are not retrieved. If they are erroneously retrieved, they are ignored during the indexing step. This file type discrimination is applied during both kinds of searching. The only difference between running the WebCrawler in indexing mode and running it in real-time search mode is the discovery strategy employed by the search engine.
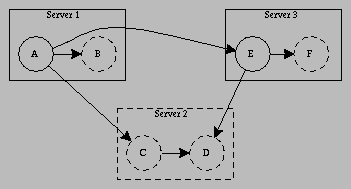
Figure 2: The Web as a graph.
Indexing mode: In indexing mode, the goal is to build an index of as much of the Web as possible. If the WebCrawler Index has enough space for 50,000 documents, which documents should those be? For a Web index, one solution is that those documents should come from as many different servers as possible. The WebCrawler takes the following approach: it uses a modified breadth-first algorithm to ensure that every server has at least one document represented in the index. The strategy is effective. The most frequent feedback about the WebCrawler is that it has great coverage and that nearly every server is represented!
In detail, a WebCrawler indexing run proceeds as follows: every time a document on a new server is found, that server is placed on a list of servers to be visited right away. Before any other documents are visited, a document on each of the new servers is retrieved and indexed. When all known servers have been visited, indexing proceeds sequentially through a list of all servers until a new one is found, at which point the process repeats. While indexing, the WebCrawler runs either for a certain amount of time, or until it has retrieved some number of documents. In the current implementation, the WebCrawler builds an index at the rate of about 1000 documents an hour on a 486-based PC running NEXTSTEP.
Real-time search mode: In real-time search mode, where the goal is to find documents that are most similar to a user's query, the WebCrawler uses a different search algorithm. The intuition behind the algorithm is that following links from documents that are similar to what the user wants is more likely to lead to relevant documents than following any link from any document. This intuition roughly captures the way people navigate the Web: they find a document about a topic related to what they are looking for and follow links from there.
To find an initial list of similar documents, the WebCrawler runs the user's query against its index. A single document can also be used as a starting point, but using the index is much more efficient. From the list, the most relevant documents are noted, and any unexplored links from those documents are followed. As new documents are retrieved, they are added to the index, and the query is re-run. The results of the query are sorted by relevance, and new documents near the top of the list become candidates for further exploration. The process is iterated either until the WebCrawler has found enough similar documents to satisfy the user or until a time limit is reached.
One problem with this approach is that the WebCrawler blindly follows links from documents, possibly leading it down an irrelevant path. For instance, if the WebCrawler is searching for pages about molecular biology it may come across a page that has links to both molecular biology resources and unrelated network resources. When people navigate, they choose links based on the anchor text, the words that describe a link to another document, and tend to follow a directed path to their destination. Ideally, the WebCrawler should choose among several of these links, preferring the one that made the most sense. Although the WebCrawler's reasoning ability is somewhat less than that of a human, it does have a basis for evaluating each link: the similarity of the anchor text to the user's query. To evaluate this similarity, the WebCrawler makes a small full-text index from the anchor text in a document and applies the users query to select the most relevant link. Searching the anchor text in this way works well, but anchor texts are usually short and full-text indexing does not work as well as it could. More sophisticated full-text tools would help greatly, particularly the application of a thesaurus to expand the anchor text.
The idea of following documents from other, similar ones was first demonstrated to work in the Fish search [DeBra]. The WebCrawler extends that concept to initiate the search using the index, and to follow links in an intelligent order.
To actually retrieve documents from the Web, the search engine invokes "agents." The interface to an agent is simple: "retrieve this URL." The response from the agent to the search engine is either an object containing the document content or an explanation of why the document could not be retrieved. The agent uses the CERN WWW library (libWWW), which gives it the ability to access several types of content with several different protocols, including HTTP, FTP and Gopher [Berners-Lee].
Since waiting for servers and the network is the bottleneck in searching, agents run in separate processes and the WebCrawler employs up to 15 in parallel. The search engine decides on a new URL, finds a free agent, and asks the agent to retrieve that URL. When the agent responds, it is given new work to do. As a practical matter, running agents in separate processes helps isolate the main WebCrawler process from memory leaks and errors in the agent and in libWWW.
The WebCrawler's database is comprised of two separate pieces: a full-text index and a representation of the Web as a graph. The database is stored on disk, and is updated as documents are added. To protect the database from system crashes, updates are made under the scope of transactions that are committed every few hundred documents.
The full-text index is currently based on NEXTSTEP's IndexingKit [NeXT]. The index is inverted to make queries fast: looking up a word produces a list of pointers to documents that contain that word. More complex queries are handled by combining the document lists for several words with conventional set operations. The index uses a vector-space model for handling queries [Salton].
To prepare a document for indexing, a lexical analyzer breaks it down into a stream of words that includes tokens from both the title and the body of the document. The words are run through a "stop list" to prevent common words from being indexed, and they are weighted by their frequency in the document divided by their frequency in a reference domain. Words that appear frequently in the document, and infrequently in the reference domain are weighted most highly, while words that appear infrequently in either are given lower weights. This type of weighting is commonly called peculiarity weighting.
The other part of the database stores data about documents, links, and servers. Entire URLs are not stored; instead, they are broken down into objects that describe the server and the document. A link in a document is simply a pointer to another document. Each object is stored in a separate btree on disk; documents in one, servers in another, and links in the last. Separating the data in this way allows the WebCrawler to scan the list of servers quickly to select unexplored servers or the least recently accessed server.
The Query Server implements the WebCrawler Index, a search service available via a document on the Web [Pinkerton]. It covers nearly 50,000 documents distributed across 9000 different servers, and answers over 6000 queries each day. The query model it presents is a simple vector-space query model on the full-text database described above. Users enter keywords as their query, and the titles and URLs of documents containing some or all of those words are retrieved from the index and presented to the user as an ordered list sorted by relevance. In this model, relevance is the sum, over all words in the query, of the product of the word's weight in the document and its weight in the query, all divided by the number of words in the query. Although simple, this interface is powerful and can find related documents with ease. Some sample query output is shown in below in Figure 3.
Search results for the query "molecular biology human genome project":
1000 Guide to Molecular Biology Databases
0754 Guide to Molecular Biology Databases
0562 Biology Links
0469 bionet newsgroups
0412 Motif BioInformatics Server
0405 LBL Catalog of Research Abstracts (1993)
0329 Molecular Biology Databases
0324 GenomeNet WWW server
0317 DOE White Paper on Bio-Informatics
0292 Molecular biology
0277 Oxford University Molecular Biology Data Centre Home Page
0262 Biology Internet Connections
0244 Harvard Biological Laboratories - Genome Research
0223 About the GenomeNet
0207 Biology Index
Figure 3: Sample WebCrawler results. For brevity, only the first 15 of 50 results are shown. The numbers down the left side of the results indicate the relevance of the document to the query, normalized to 1000 for the most relevant document. At the top of the list, two documents have the same title. These are actually two different documents, with different URLs and different weights.
The time required for the Query Server to respond to a query averages about an eighth of a second. That interval includes the time it takes to parse the query, call the database server, perform the query, receive the answer, format the results in HTML and return them to the HTTP server. Of that time, about half is spent actually performing the query.
The WebCrawler has been active on the Web for the last six months. During that time, it has indexed thousands of documents, and answered nearly a quarter of a million queries issued by over 23,000 different users. This experience has put me in touch with many users and taught me valuable lessons. Some of the more important ones are summarized here. My conclusions are based on direct interaction with users, and on the results of an on-line survey of WebCrawler users that has been answered by about 500 people.
The first lesson I learned is that content-based indexing is necessary, and works very well. At the time the WebCrawler was unleashed on the Web, only the RBSE Spider indexed documents by content [Eichmann]. Other indexes like the Jumpstation and WWWW did not index the content of documents, relying instead on the document title inside the document, and anchor text outside the document [Fletcher, McBryan].
Indexing by titles is a problem: titles are an optional part of an HTML document, and 20% of the documents that the WebCrawler visits do not have them. Even if that figure is an overestimate of the missing titles in the network as a whole, basing an index only on titles would omit a significant fraction of documents from the index. Furthermore, titles don't always reflect the content of a document.
By indexing titles and content, the WebCrawler captures more of what people want to know. Most people who use the WebCrawler find what they are looking for, although it takes them several tries. The most common request for new features in the WebCrawler is for more advanced query functionality based on the content index.
Information retrieval systems are usually measured in two ways: precision and recall [Salton]. Precision measures how well the retrieved documents match the query, while recall indicates what fraction of the relevant documents are retrieved by the query. For example, if an index contained ten documents, five of which were about dolphins, then a query for `dolphin-safe tuna' that retrieved four documents about dolphins and two others would have a precision of 0.66 and a recall of 0.80.
Recall is adequate in the WebCrawler, and in the other indexing systems available on the Internet today: finding enough relevant documents is not the problem. Instead, precision suffers because these systems give many false positives. Documents returned in response to a keyword search need only contain the requested keywords and may not be what the user is looking for. Weighting the documents returned by a query helps, but does not completely eliminate irrelevant documents.
Another factor limiting the precision of queries is that users do not submit well-focused queries. In general, queries get more precise as more words are added to them. Unfortunately, the average number of words in a query submitted to the WebCrawler is 1.5, barely enough to narrow in on a precise set of documents. I am currently investigating new ways to refine general searches and to give users the ability to issue more precise queries.
The broad index built by the breadth-first search ensures that every server with useful content has several pages represented in the index. This coverage is important to users, as they can usually naviagte within a server more easily than navigating across servers. If a search tool identifies a server as having some relevant information, users will probably be able to find what they are looking for.
Using this strategy has another beneficial effect: indexing documents from one server at a time spreads the indexing load among servers. In a run over the entire Web, each server might see an access every few hours, at worst. This load is hardly excessive, and for most servers is lost in the background of everyday use. When the WebCrawler is run in more restricted domains (for instance, here at the University of Washington), each server will see more frequent accesses, but the load is still less than that of other search strategies.
The main advantage of the WebCrawler is that it is able to operate on the the Web today. It uses only the protocols that make the Web operate and does not require any more organizational infrastructure to be adopted by service providers.
Still, Web robots are often criticized for being inefficient and for wasting valuable Internet resources because of their uninformed, blind indexing. Systems like ALIWEB and Harvest are better in two ways. First, they use less network bandwidth than robots by locally indexing and transferring summaries only once per server, instead of once per document. Second, they allow server administrators to determine which documents are worth indexing, so that the indexing tools need not bother with documents that are not useful.
Although Web robots are many times less efficient than they could be, the indexes they build save users from following long chains before they find a relevant document, thus saving the Internet bandwidth. For example, if the WebCrawler indexes 40,000 documents and gets 5000 queries a day, and if each query means the user will retrieve just three fewer documents than she otherwise would have, then it will take about eight days for the WebCrawler's investment in bandwidth to be paid back.
Another advantage of the document-by-document behavior of Web robots is that they can apply any indexing algorithm because they have the exact content of the document to work from. Systems that operate on summaries of the actual content are dependent on the quality of those summaries, and to a lesser extent, on the quality of their own indexing algorithm. One of the most frequent requests for new WebCrawler features is a more complex query engine. This requires a more complex indexing engine, for which original document content may be necessary. Putting such indexing software on every server in the world may not be feasible.
To help robots avoid indexing useless or unintelligible documents, Martin Koster has proposed a standard that helps guide robots in their choice of documents [Koster2]. Server administrators can advise robots by specifying which documents are worth indexing in a special "robots.txt" document on their server. This kind of advice is valuable to Web robots, and increases the quality of their indexes. In fact, some administrators have gone so far as to create special overview pages for Web robots to retrieve and include.
The future of client-initiated searching, like running the WebCrawler in on-demand mode, is still in doubt because of the load it places on the network. It is one thing for a few robots to be building indexes and running experiments; it is quite another for tens of thousands of users to be unleashing multiple agents under robotic control. Fortunately, most robot writers seem to know this and have declined to release their software publicly.
The key difference between running a private robot and running an index-building one is that the results of the private robot are only presented to one person. They are not stored and made available for others, so the cost of building them is not amortized across many queries.
In the short term, the WebCrawler will evolve in three ways. First, I am exploring better ways to do client-based searching. This work centers on more efficient ways to determine which documents are worth retrieving and strategies that allow clients to perform searches themselves and send the results of their explorations back to the main WebCrawler index. The rationale behind the second idea is that if the results of these explorations are shared, then searching by clients may be more feasible.
Second, I am exploring possibilities for including a more powerful full-text engine in the WebCrawler. Several new features are desirable; the two most important are proximity searching and query expansion and refinement using a thesaurus. Proximity searching allows several words to be considered as a phrase, instead of as independent keywords. Using a thesaurus is one way to help target short, broad queries: a query of biology may find many documents containing the word biology, but when expanded by a thesaurus to include more terms about biology, the query will more precisely recognize documents about biology. Finally, I plan on working with the Harvest group to see if the WebCrawler can fit into their system as a broker [Bowman].
The WebCrawler is a useful Web searching tool. It does not place an undue burden on individual servers while building its index. In fact, the frequent use of its index by thousands of people saves the Internet bandwidth. The real-time search component of the WebCrawler is effective at finding relevant documents quickly, but it has the aforementioned problem of not scaling well given the limited bandwidth of the Internet.
In building the WebCrawler, I have learned several lessons. First, full-text indexing is worth the extra time and space it takes to create and maintain the index. In a Web robot, there is no additional load network load imposed by full-text index; the load occurs only at the server. Second, when large numbers of diverse documents are present together in an index, achieving good query precision is difficult. Third, using a breadth-first search strategy is a good way to build a Web-wide index.
The most important lesson I have learned from the WebCrawler and other robots like it is that they are completely consistent with the character of the decentralized Web. They require no centralized decision making and no participation from individual site administrators, other than their compliance with the protocols that make the Web operate in the first place. This separation of mechanism and policy allows each robot to pick its policy and offer its own unique features to users. With several choices available, users are more likely to find a search tool that matches their immediate needs, and the technology will ultimately mature more quickly.
I would like to thank Dan Weld for his support and many insightful discussions. I would also like to thank the thousands of WebCrawler users on the Internet: they have provided invaluable feedback, and put up with many problems in the server. I'm grateful to Tad Pinkerton and Rhea Tombropoulos for their editing assistance.
[Bowman] Bowman, C. M. et al. The Harvest Information Discovery and Access System. Second International World-Wide Web Conference, Chicago, 1994.
[Berners-Lee] Berners-Lee, T., Groff, J., Frystyk, H. Status of the World-Wide Web Library of Common Code
[DeBra] DeBra, P. and Post, R. Information Retrieval in the World-Wide Web: Making Client-based searching feasible, Proceedings of the First International World-Wide Web Conference, R. Cailliau, O. Nierstrasz, M. Ruggier (eds.), Geneva, 1994.
[Fletcher] Fletcher, J. The Jumpstation.
[McBryan] McBryan, O. GENVL and WWWW: Tools for Taming the Web, Proceedings of the First International World-Wide Web Conference, R. Cailliau, O. Nierstrasz, M. Ruggier (eds.), Geneva, 1994.
[Koster2] Koster, M. Guidelines for Robot Writers.
[NeXT] NeXT Computer, Inc. NEXTSTEP General Reference, Volume 2. Addison-Wesley, 1992.
[Pinkerton] Pinkerton, C. B. The WebCrawler Index
[Salton] Salton, G. Automatic Text Processing: The Transformation, Analysis, and Retrieval of Information by Computer, Addison Wesley, 1989.
Brian Pinkerton is a Ph.D. student in the Department of Computer Science and Engineering at the University of Washington in Seattle. He is the author and operator of the WebCrawler, a popular Internet search tool. His professional interests include network information discovery, information retrieval, and applications of computer science to molecular biology. He recently returned from a four year leave of absence, during which he worked as a software engineer at NeXT Computer.